Autocorrected Typing Software
本实验项目搬运自加州大学伯克利分校的CS61A课程的Cats项目。
我们知道CS61A是一门世界知名的计算机编程入门课程,相关课程实验和项目网上都有答案, 但是请遵守学术诚信原则,自己动手完成所有的实验,这样你才能得到足够的训练, 掌握Python这门语言,为后续的实践课程打下坚实的基础。
项目 2:自动更正打字软件

程序员抽象、递归和 快速打字的梦想。
介绍
试着按顺序尝试问题,因为后面的一些问题建立在前面问题的基础上,因此在运行ok测试时也是如此。
在此项目中,您将编写一个测量打字速度的程序。此外,您还将实现键入自动更正的功能,即在用户键入单词后尝试更正单词拼写。这个项目的灵感来自typeracer。
当学生在没有仔细阅读问题描述的情况下尝试实现这些功能时,他们经常会遇到问题。😱 在开始编码之前仔细阅读每个描述。
完成品
我们的员工对该项目的解决方案可以在 cats.cs61a.org上进行交互。如果您愿意,请立即尝试一下。当您完成该项目时,您将自己实现了这场比赛的重要部分!
下载入门文件
您可以将所有项目代码下载为zip 存档。该项目包含多个文件,但您的更改将仅针对 cats.py. 以下是存档中包含的文件:
- cats.py:打字测试逻辑。
- utils.py:与文件和字符串交互的实用函数。
- ucb.py:CS 61A 项目的实用功能。
- data/sample_paragraphs.txt:包含要输入的文本示例的文件。这些是 关于各种主题的维基百科文章。
- data/common_words.txt:包含按频率排列的常见英语单词的文件 。
- data/words.txt:包含更多 按频率排列的英语单词的文件。
- data/final_diff_words.txt:包含更多英文单词的文件!
- cats_gui.py:用于基于 Web 的图形用户界面 (GUI) 的 Web 服务器。
- gui_files:图形用户界面 (GUI) 所需的文件目录。
- multiplayer:支持多人模式所需的文件目录。
- favicons:图标目录。
- images:图像目录。
- ok, proj02.ok, tests: 测试文件。
后勤
您将上交以下文件:
- cats.py
您无需修改或提交任何其他文件即可完成该项目。
对于我们要求您完成的功能,我们可能会提供一些初始代码。如果您不想使用该代码,请随意删除它并从头开始。您还可以根据需要添加新的函数定义。
但是,请不要修改任何其他功能或编辑上面未列出的任何文件。这样做可能会导致您的代码无法通过我们的自动评分器测试。另外,请不要更改任何函数签名(名称、参数顺序或参数数量)。
在整个项目中,您应该测试代码的正确性。经常测试是一个很好的做法,这样就可以轻松隔离任何问题。但是,您不应该过于频繁地进行测试,以便让自己有时间思考问题。
我们提供了一个自动评分器ok来帮助您测试代码并跟踪您的进度。第一次运行自动评分器时,系统会要求您使用网络浏览器使用 Ok 帐户登录。请这样做。每次运行时ok,它都会在我们的服务器上备份您的工作和进度。
ok的主要目的是测试您的实现。
如果你想以交互方式测试你的代码,你可以运行
python ok -q [题号] -i
插入适当的问题编号(例如01)。这将运行该问题的测试,直到您的第一个失败,然后让您有机会以交互方式测试您编写的函数。
您还可以通过编写以下内容来使用 OK 中的调试打印功能
print(“DEBUG:”,x)
这将在您的终端中产生输出,而不会导致 OK 测试因额外输出而失败。
第一阶段:打字
当学生在没有仔细阅读问题描述的情况下尝试实现这些功能时,他们经常会遇到问题。😱 在开始编码之前仔细阅读每个描述。
问题 1 (1 分)
在整个项目中,我们将对cats.py.
实施pick. 此函数选择用户将键入的段落。它需要三个参数:
- 称为的段落(字符串)列表paragraphs
- 一个select函数,返回True可以选择的段落
- 非负索引k
该pick函数返回select为True的第k段落。如果不存在这样的段落(因为k太大),则 pick返回空字符串。
在编写任何代码之前,请解锁测试以验证您对问题的理解:
python ok -q 01 -u
完成解锁后,开始实施您的解决方案。您可以通过以下方式检查您的正确性:
python ok -q 01
问题2(2分)
实现about,它需要一个单词列表subject。它返回一个函数,该函数接受一个段落并返回一个布尔值,指示该段落是否包含subject 中的任何单词。
一旦我们实现了about,我们就能够将传递返回的select函数作为 pick的参数,这在我们继续实现我们的类型测试时将很有用。
为了能够准确地进行比较,您需要忽略段落中的大小写(即,假设大写和小写字母不会改变它是什么单词)和标点符号。此外,仅检查段落中主题中的单词是否完全匹配,而不检查子字符串。例如,“dogs”与单词“dog”不匹配。
提示:您可以使用 utils.py中的字符串实用函数。您可以参考实用程序函数的文档字符串来了解它们的使用方式。
在编写任何代码之前,请解锁测试以验证您对问题的理解:
python ok -q 02 -u
完成解锁后,开始实施您的解决方案。您可以通过以下方式检查您的正确性:
python ok -q 02
问题3(2分)
实现 accuracy,需要一个typed段落和一个source 段落。它返回 typed中与source中相应单词完全匹配的单词的百分比。大小写和标点符号也必须匹配。这里的“对应”意味着两个单词必须出现在typed和source中的相同索引处— 两个段落的第一个单词必须匹配,两个单词的第二个单词必须匹配,依此类推。
此上下文中的单词是通过空格与其他单词分隔开的任何字符序列,因此请对待“dog;” 作为一个单词。
如果typed长于source,则typed 中没有对应单词的source多余单词都是错误的。
如果 typed和source均为空,则精度为 100.0。如果typed为空但source不为空,则精度为零。如果typed不为空而是source为空,则精度为零。
在编写任何代码之前,请解锁测试以验证您对问题的理解:
python ok -q 03 -u
完成解锁后,开始实施您的解决方案。您可以通过以下方式检查您的正确性:
python ok -q 03
问题 4(1 分)
实现 wpm,它计算每分钟的单词数,这是给定字符串typed和以秒为单位的时间量elapsed的打字速度度量。 尽管它的名字是这样的,但每分钟的单词数并不是基于输入的单词数,而是基于 5 个字符的组数,因此打字测试不会因单词的长度而产生偏差。每分钟字数的公式是键入的字符数(包括空格)除以 5(典型字长)与所用时间(以分钟为单位)的比率。
例如,字符串"I am glad!"包含三个单词和十个字符(不包括引号)。每分钟字数计算使用 2 作为键入的字数(因为 10 / 5 = 2)。如果有人在 30 秒(半分钟)内输入该字符串,那么他们的速度将为每分钟 4 个单词。
在编写任何代码之前,请解锁测试以验证您对问题的理解:
python ok -q 04 -u
完成解锁后,开始实施您的解决方案。您可以通过以下方式检查您的正确性:
python ok -q 04
考验你打字速度的时候到了!您可以使用命令行来测试有关特定主题的段落的打字速度。例如,下面的命令将加载有关猫或小猫的段落。如果您好奇的话,请参阅run_typing_test 实现的函数(但它是为您定义的)。
python cats.py -t cats kittens
您可以使用以下命令尝试基于 Web 的图形用户界面 (GUI)。(关闭浏览器中的选项卡后,您可能必须在终端上使用Ctrl+C或Cmd+C来退出 GUI)。
python cats_gui.py
提交您的第一阶段检查点
检查并确保您已完成第一阶段中的所有问题:
python ok --score
当您运行ok命令时,您仍然会看到一些测试被锁定,因为您尚未完成整个项目。如果您完成了到目前为止的所有问题,您将获得检查点的满分。
第二阶段:自动更正
当学生在没有仔细阅读问题描述的情况下尝试实现这些功能时,他们经常会遇到问题。😱 在开始编码之前仔细阅读每个描述。
在基于 Web 的 GUI 中,有一个自动更正按钮,但现在它没有任何作用。让我们实现自动纠正拼写错误。每当用户按下空格键时,如果他们输入的最后一个单词与字典中的单词不匹配但接近,那么该相似的单词将替换他们输入的内容。
问题5(2分)
实现autocorrect,需要一个 typed_word、 一个 word_list、 一个diff_function和 一个limit。 autocorrect的目标是返回word_list中提供最接近typed_word的单词。
具体来说,autocorrect做了以下几件事:
- 如果typed_word包含在word_list内,autocorrect 则返回该单词。
- 否则,根据 diff_function返回word_list中与提供的typed_word差异最小的单词。
- 但是,如果typed_word和word_list 中的任何单词之间的最小差异大于limit,则返回typed_word 。也就是说,limit对纠正错误的严重程度设置了“限制”。
注意:假设typed_word和 的所有元素word_list都是小写且没有标点符号。
重要提示:如果 word_list中的多个字符串与typed_word的差异最小,则autocorrect应返回最接近 word_list前面的字符串。
一个diff 函数接受三个参数。第一个是typed_word,第二个是源单词(在本例中是来自 的单词word_list),第三个参数是 limit。diff 函数的输出是一个数字,表示两个字符串之间的差异量。
以下是 diff 函数的示例,该函数计算两个输入字符串的最小值1 + limit 和长度差:
>>> def length_diff(w1, w2, limit):
return min(limit + 1, abs(len(w2) - len(w1)))
>>> length_diff('mellow', 'cello', 10)
1
>>> length_diff('hippo', 'hippopotamus', 5)
6
提示:尝试将max或者min与可选key参数一起使用(它采用单参数函数)。例如,max([-7, 2, -1], key = abs)将返回,-7因为abs(-7)大于abs(2)和abs(-1)。
在编写任何代码之前,请解锁测试以验证您对问题的理解:
python ok -q 05 -u
完成解锁后,开始实施您的解决方案。您可以通过以下方式检查您的正确性:
python ok -q 05
问题6(3分)
实现 feline_fixes,这是一个需要两个字符串的 diff 函数。它返回typed单词中必须更改的最小字符数, 以便将其转换为source单词。如果字符串的长度不相等,则长度差将添加到总数中。
重要提示:您不能在实现中使用while、for或列表推导式。请使用递归。
这里有些例子:
>>> big_limit = 10
>>> feline_fixes("nice", "rice", big_limit) # Substitute: n -> r
1
>>> feline_fixes("range", "rungs", big_limit) # Substitute: a -> u, e -> s
2
>>> feline_fixes("pill", "pillage", big_limit) # Don't substitute anything, length difference of 3.
3
>>> feline_fixes("goodbye", "good", big_limit) # Don't substitute anything, length difference of 3.
3
>>> feline_fixes("roses", "arose", big_limit) # Substitute: r -> a, o -> r, s -> o, e -> s, s -> e
5
>>> feline_fixes("rose", "hello", big_limit) # Substitute: r->h, o->e, s->l, e->l, length difference of 1.
5
重要提示: 如果必须更改的字符数大于limit,则feline_fixes应返回大于limit的任何数字,并应最大限度地减少所需的计算量。
为什么要这么做呢?我们知道autocorrect将拒绝任何与source 单词差异大于 limit的typed单词。差异比limit大1 或 100并不重要;自动更正同样会拒绝它。因此,一旦我们知道差异将高于limit,即使返回的差异不完全正确,尝试最小化额外计算也是有意义的。
这两个调用feline_fixes应该花费大约相同的时间来评估:
>>> limit = 4
>>> feline_fixes("roses", "arose", limit) > limit
True
>>> feline_fixes("rosesabcdefghijklm", "arosenopqrstuvwxyz", limit) > limit
True
在编写任何代码之前,请解锁测试以验证您对问题的理解:
python ok -q 06 -u
完成解锁后,开始实施您的解决方案。您可以通过以下方式检查您的正确性:
python ok -q 06
尝试在 GUI 中打开自动更正。它可以帮助您更快地打字吗?修正是否准确?
问题7(3分)
实现minimum_mewtations ,这是一个 diff 函数,它返回将typed单词转换为source单词所需的最少编辑操作数。
编辑操作分为三种,举例如下:
- 添加一个字母到typed.
- 添加"k"到"itten"给我们带来"kitten".
- 从typed中删除一个字母。
- "s"从中删除"scat"给我们"cat"。
- 将一个typed中的字母替换为另一个字母。
- 将"zaguar"中的"z"替换为"j"得到"jaguar".
每个编辑操作都会为两个单词之间的差异贡献 1。
>>> big_limit = 10
>>> minimum_mewtations("cats", "scat", big_limit) # cats -> scats -> scat
2
>>> minimum_mewtations("purng", "purring", big_limit) # purng -> purrng -> purring
2
>>> minimum_mewtations("ckiteus", "kittens", big_limit) # ckiteus -> kiteus -> kitteus -> kittens
3
我们在cats.py中提供了一个实现的模板。您可以根据需要修改模板或将其完全删除。
提示: 这是一个具有 3 次递归调用的递归函数。这些递归调用之一将类似于 中的递归调用feline_fixes。此外,您将需要多个基本案例来解决这一问题。
重要提示: 如果所需的编辑数量大于limit,则minimum_mewtations应返回任何大于该数量的数字limit,并应最大限度地减少所需的计算量。
这两个minimum_mewtations调用应该花费大约相同的时间来评估:
>>> limit = 2
>>> minimum_mewtations("ckiteus", "kittens", limit) > limit
True
>>> minimum_mewtations("ckiteusabcdefghijklm", "kittensnopqrstuvwxyz", limit) > limit
True
在编写任何代码之前,请解锁测试以验证您对问题的理解:
python ok -q 07 -u
完成解锁后,开始实施您的解决方案。您可以通过以下方式检查您的正确性:
python ok -q 07
再次尝试输入。修正是否更准确?
python cats_gui.py
(可选)扩展:最终差异(0 分)
您可以选择设计自己的 diff 函数,称为 final_diff. 以下是一些进行更准确修正的想法:
- 考虑哪些添加和删除比其他更有可能。例如,如果某个字母连续出现两次,您很可能会不小心漏掉该字母。
- 将交换位置的两个相邻字母视为一次更改,而不是两次更改。
- 尝试合并常见的拼写错误。
您还可以通过更改cats.py中变量FINAL_DIFF_LIMIT的值来设置 diff 函数使用的限制。
您可以final_diff通过运行以下命令来检查您的成功率:
python score.py
如果您不知道从哪里开始,请尝试将feline_fixes 和minimum_mewtations代码复制粘贴到final_diff中并对其进行评分。看看他们无意中修正的拼写错误可能会给你一些想法!
第三阶段:多人游戏
当学生在没有仔细阅读问题描述的情况下尝试实现这些功能时,他们经常会遇到问题。😱 在开始编码之前仔细阅读每个描述。
和朋友一起打字更有趣!您现在将实现多人游戏功能,以便当您在计算机上运行cats_gui.py时,它会连接到cats.cs61a.org上的课程服务器 并寻找其他人进行比赛。
为了与朋友比赛,将运行 5 个不同的程序:
- 您的 GUI,它是一个处理所有文本着色并在 Web 浏览器中显示的程序。
- 您的cats_gui.py,它是一个 Web 服务器,它使用您编写的代码与您的 GUI 在cats.py上进行通信。
- 你对手的cats_gui.py.
- 你对手的 GUI。
- CS 61A 多人游戏服务器,用于将玩家匹配在一起并传递消息。
当您键入时,您的 GUI 会将您键入的内容上传到cats_gui.py服务器,服务器会计算您取得的进度并返回进度更新。它还会将进度更新上传到多人游戏服务器,以便对手的 GUI 可以显示它。
同时,您的 GUI 显示始终试图通过从cats_gui请求进度更新来保持最新状态.py,而后者又从多人游戏服务器请求该信息。
每个玩家都有一个id号码,服务器使用该号码来跟踪打字进度。
问题8(2分)
实现 report_progress,每次用户完成输入单词时都会调用它。它需要一个typed单词列表、prompt单词列表、用户的user_id以及一个用于将进度报告上传到多人游戏服务器的upload函数。typed中的单词永远不会比 prompt中的单词更多。
您的进度是您正确输入的prompt单词与第一个错误单词之间即直到第一个错误单词为止除以prompt 单词数的比率。例如,此示例的进度为0.25:
report_progress(["Hello", "ths", "is"], ["Hello", "this", "is", "wrong"], ...)
您的report_progress函数应该做两件事:将消息上传到多人游戏服务器并返回带有 user_id的玩家进度。
您可以通过在包含键'id'和'progress' 的 upload 二元素字典上调用该函数来将消息上传到多人服务器。然后您应该返回玩家的进度,即您计算的单词的比率。
提示: 请参阅下面的字典,了解该函数的潜在输入示例upload 。这本字典代表的是user_id1 和progress0.6的玩家。
{'id': 1, 'progress': 0.6}
在编写任何代码之前,请解锁测试以验证您对问题的理解:
python ok -q 08 -u
完成解锁后,开始实施您的解决方案。您可以通过以下方式检查您的正确性:
python ok -q 08
问题9(2分)
实现 time_per_word,它接收一个words列表和 每个玩家times_per_player列表(包含时间戳words,指示每个玩家何时完成了单词中每个单词的输入),它返回一个match带有的给定信息 。
Amatch是一个数据抽象,表示多个玩家之间的打字“匹配”。具体来说,每个都match存储实例变量words和times。
- times存储为每个玩家在每个单词所花费的时间words的列表。
- 具体来说,times[i][j]表示玩家i输入words[j]花费了多长时间。
例如,说words = ['Hello', 'world'] 和times = [[5, 1], [4, 2]],则[5, 1]对应于玩家 0 的时间列表,并[4, 2]对应于玩家 1 的时间列表。因此,玩家 0 花费了5单位时间来写单词'Hello'。
重要提示match:返回 时请务必使用构造函数match。测试将检查您是否正在使用match数据抽象,而不是假设特定的数据格式。
match有关更多信息,您可以阅读下面或cats.py中的构造函数的定义。然而,与任何数据抽象一样,我们只关心我们的函数做什么而不是它们的具体实现!
匹配数据抽象 (enable JavaScript)
def match(words, times):
"""包含所有键入的单词及其时间的数据抽象。
Arguments:
words: 字符串列表,每个字符串代表键入的一个单词。
times: 每个玩家输入每个单词所花费的时间的列表。
times[i][j] = 玩家 i 输入单词所花费的时间[j]。
输入示例:
words: ['Hello', 'world']
times: [[5, 1], [4, 2]]
"""
assert all([type(w) == str for w in words]), 'words应该是字符串列表'
assert all([type(t) == list for t in times]), 'times应该是字符串列表'
assert all([isinstance(i, (int, float)) for t in times for i in t]), 'times应包含数字'
assert all([len(t) == len(words) for t in times]), '每次应该有一个单词.'
return {"words": words, "times": times}
def get_word(match, word_index):
"""获取索引为 word_index 的单词的实用函数"""
assert 0 <= word_index < len(get_all_words(match)), "word_index 超出单词范围"
return get_all_words(match)[word_index]
def time(match, player_num, word_index):
"""一个用于计算took player_num在word_index处输入单词所花费时间的实用函数"""
assert word_index < len(get_all_words(match)), "word_index 超出单词范围"
assert player_num < len(get_all_times(match)), "player_num 超出玩家范围"
return get_all_times(match)[player_num][word_index]
def get_all_words(match):
"""匹配中所有单词的选择器函数"""
return match["words"]
def get_all_times(match):
"""适用于所有玩家所有打字时间的选择器功能"""
return match["times"]
def match_string(match):
"""一个辅助函数,它接受匹配数据抽象并返回它的字符串表示形式"""
return f"match({get_all_words(match)}, {get_all_times(match)})"
时间戳是累积的并且始终在增加,而 times中的值是 每个玩家的连续时间戳之间的差异。
下面是一个示例: 如果times_per_player = [[1, 3, 5], [2, 5, 6]] 则match的相应times属性将为[[2, 2], [3, 1]]。这是因为第一个玩家的 时间戳差异为(3-1)(5-3) ,第二个玩家的时间戳差异为(5-2)(6-5)。其中times_per_player每个列表的第一个值代表每个玩家的初始开始时间。
在编写任何代码之前,请解锁测试以验证您对问题的理解:
python ok -q 09 -u
完成解锁后,开始实施您的解决方案。您可以通过以下方式检查您的正确性:
python ok -q 09
问题10(2分)
实现 fastest_words,它返回每个玩家输入最快的单词。一旦所有玩家都完成输入,就会调用此函数。它需要一个match.
具体来说,该fastest_words函数返回一个单词列表列表,每个玩家一个列表,以及每个列表中他们输入最快的单词(相对于所有其他玩家)。如果出现平局,则将列表中最早的玩家(最小的玩家索引)视为输入速度最快的玩家。
例如,考虑以下与单词'Just'、'have'和 'fun'的匹配。玩家 0 打字'fun'最快(3 秒),玩家 1 打字'Just'最快(4 秒),并且他们在单词上打成平手'have'(都花了 1 秒),所以我们认为玩家 0 是最快的,因为他们是最早的玩家列表。
>>> player_0 = [5, 1, 3]
>>> player_1 = [4, 1, 6]
>>> fastest_words(match(['Just', 'have', 'fun'], [player_0, player_1]))
[['have', 'fun'], ['Just']]
该match参数是一种match数据抽象,就像我们在问题 9 中返回的那样。
- match您可以使用选择器访问 a 中的单词get_word,该选择器接受一个match和 word_index(一个整数)。
- 此外,您可以使用time函数访问玩家在特定索引处键入单词所花费的时间,该函数除了 match和word_index之外还需要一个整数player_num。
- 通过这两个函数和一个 match,我们可以轻松获取任何玩家输入任何单词所花费的时间!
>>> player_0 = [5, 1, 3]
>>> player_1 = [4, 1, 6]
>>> ex_match = match(['Just', 'have', 'fun'], [player_0, player_1])
>>> get_word(ex_match, 2)
'fun'
>>> time(ex_match, 0, 2)
3
重要提示match:返回 时请务必使用构造函数match。测试将检查您是否正在使用match数据抽象,而不是假设特定的数据格式。
确保您的实现不会改变给定的玩家输入列表。对于上面的示例,调用fastest_wordson[player_0, player_1] 不应改变player_0或player_1。
在编写任何代码之前,请解锁测试以验证您对问题的理解:
python ok -q 10 -u
完成解锁后,开始实施您的解决方案。您可以通过以下方式检查您的正确性:
python ok -q 10
恭喜!现在您可以在课程中与其他学生对战。设置cats.py中靠近底部的enable_multiplayer为True并快速输入!
python cats_gui.py
第四阶段:效率(额外学分)
问题 EC (1 分)
在办公时间和项目聚会期间,工作人员将优先帮助学生解决所需的问题。除非队列为空,否则我们不会提供有关此问题的帮助 。
在这个问题中,您将实现记忆化装饰器,它将通过“记住”特别密集的操作的结果来提高我们程序的效率。
确保您熟悉装饰器和记忆。如果您想回顾一下,请打开下面的下拉框以获取更多信息。
装饰器 (enable JavaScript)
Python 装饰器允许您修改预先存在的函数而不更改函数的结构。
具体来说,装饰器函数是一个高阶函数......
- 将原始函数作为输入
- 返回具有修改功能的新函数
- 这个新函数必须包含与原始函数相同的参数
执行两次单输入函数的装饰器示例如下所示:
>>> def do_twice(original_function):
... def repeat(x):
... original_function(x)
... original_function(x)
... return repeat
我们可以在多种情况下应用这个函数:
# Printing a value twice
>>> @do_twice
... def print_value(x):
... print(x)
...
>>> print_value(5)
5
5
# Adding an item to a list twice
>>> lst = []
>>> @do_twice
... def add_to_list(item):
... lst.append(item)
...
>>> add_to_list(5)
>>> lst
[5, 5]
另外,请注意,我们也可以直接调用装饰器函数,而不是使用@符号(即print_value = do_twice(print_value))。但是,将装饰器直接放置在我们正在修改的函数上方通常很有用,因为它们更好地描述了如何在代码中更改这些函数。
记忆化 (enable JavaScript)
请注意,我们在前面的问题中编写的 diff 函数效率非常低:您可能会发现计算机会多次进行相同的递归调用。对于具有多个参数和三个递归调用的函数,这可能更难看到。使用讲座中定义的函数可以更容易地首先看到这一点fib。
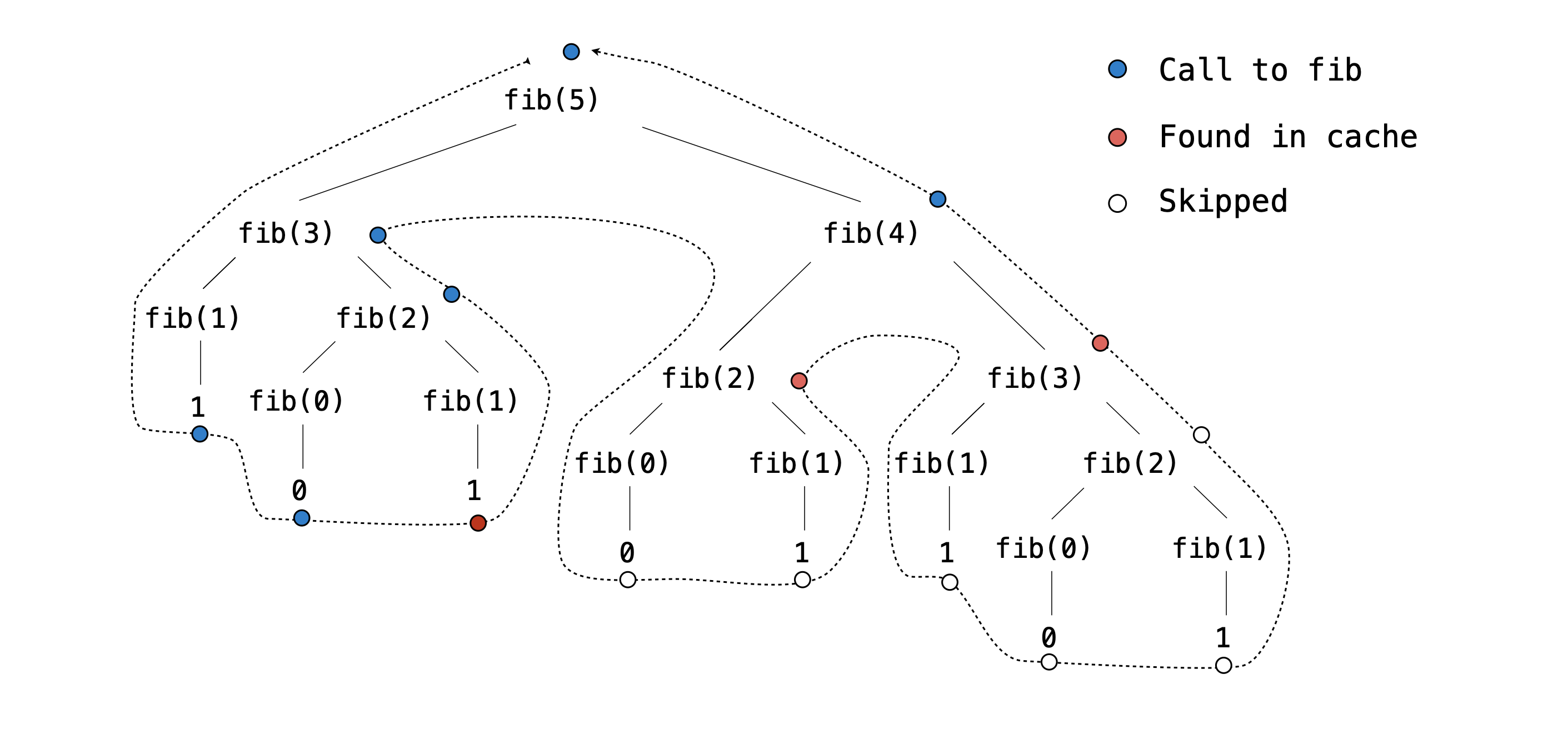
注意上面的树图中有多少冗余递归调用。我们的目标是让我们的程序存储评估递归调用的过去结果,以便在将来出现相同的递归调用时我们可以重用它们。例如,fib(5)调用的第一个分支fib(3)尚未被评估。所以我们必须遍历它后续的所有递归调用来找到它的返回值。fib(3)然而,当我们遇到对that is 的一个分支的调用时fib(4),我们之前已经找到了它的返回值!因此,如果我们有一种方法在缓存中存储和检索该信息,我们就可以避免不必要的计算。我们不再需要对其分支fib(1)和进行任何后续递归调用fib(2)。这就是记忆化的概念:将昂贵的计算结果存储在缓存中,并在执行重复操作时从缓存中检索信息。
我们将使用两个记忆装饰器。memo是一个通用的通用装饰器,可以记住它所注释的函数。如果memo遇到它没有见过的输入,它会将计算结果存储到它的cache. 如果memo接收到它已经看到的输入,它将获取 中存储的值cache并直接返回它,而不进行任何额外的计算。我们为您提供了全面实施memo。
你的任务是实施memo_diff。memo_diff是一个高阶函数,它接受一个diff_function并返回另一个名为 that 的 diff 函数memoized,与所有 diff 函数一样,接受typed、source和limit。memoized应执行以下操作:
- 当第一次memoized看到 ( typed,source ) 对时,它应该使用diff_function计算差异并缓存该值以及用作 (value ,limit ) 元组对的limit。
- 如果再次memoized遇到 ( typed, source) 对,如果提供的limit小于或等于缓存限制,则应返回记忆的value 。否则,应重新计算、重新缓存并返回差异。
重要提示:实现此函数时,请确保使用元组而不是列表将值对存储在缓存中。在字典中,键必须是不可变的(这就是为什么使用元组可以,但使用列表则不行)。
如果您好奇为什么memo_diff与这种方式不同memo并以这种方式实现,请参考下面的下拉列表:
更多信息 (enable JavaScript)
有何memo不同memo_diff?虽然memo仅存储函数调用的结果,但memo_diff考虑了附加约束 ,limit该约束影响是否可以使用缓存的结果。当使用 (typed ,source )memo_diff对调用该函数时,它不仅仅检查该对limit是否以前见过;还检查limit是否小于或等于缓存的。这是一项memo不执行的附加检查。
为什么要limit这样处理呢?我们已经知道 代表limitdiff 函数关心的最大差异,也就是说,高于 的差异可能limit是相同的。因此,当差值低于限制时,diff 函数将提供准确的差值,而当差值高于限制时,则提供不准确的差值。因此,如果缓存的差值是使用较高的限制计算的,我们可以信任它,但我们不能信任使用较低的限制计算的差异值。
例如,下面第一个调用的结果将允许我们预测第二个调用的结果。更高的限制为我们提供了更多的信息。然而,第二次调用不允许我们预测第一个调用。
>>> minimum_mewtations("hello", "hasldfasdfsffsfasdf", 100)
17
>>> minimum_mewtations("hello", "hasldfasdfsffsfasdf", 2)
3
实施后memo_diff,请完成以下操作:
- 装饰autocorrect用memo.
- 装饰minimum_mewtations用memo_diff.
运行autocorrect和minimum_mewtations现在应该快得多了!
注意:自动评分器运行需要一些时间,但不应超过 10 秒。
在编写任何代码之前,请解锁测试以验证您对问题的理解:
python ok -q EC -u
完成解锁后,开始实施您的解决方案。您可以通过以下方式检查您的正确性:
python ok -q EC
完结
运行ok所有问题以确保所有测试均已解锁并通过:
python ok
您还可以检查您在项目每个部分的分数:
python ok --score